小延迟大吞吐:LMAX架构(1)
小延迟大吞吐:LMAX架构(1)
LMAX是一种新型零售金融交易平台,它能够以很低的延迟(latency)产生大量交易(吞吐量). 这个系统是建立在JVM平台上,核心是一个业务逻辑处理器,它能够在一个线程里每秒处理6百万订单. 业务逻辑处理器完全是运行在内存中(in-memory),使用事件源驱动方式(event sourcing). 业务逻辑处理器的核心是Disruptors,这是一个并发组件,能够在无锁的情况下实现网络的Queue并发操作。他们的研究表明,现在的所谓高性能研究方向似乎和现代CPU设计是相左的。

过去几年我们不断提供这样声音:免费午餐已经结束。我们不再能期望在单个CPU上获得更快的性能,因此我们需要写使用多核处理的并发软件,不幸的是, 编写并发软件是很难的,锁和信号量是很难理解的和难以测试,这意味着我们要花更多时间在计算机上,而不是我们的领域问题,各种并发模型,如Actors 和软事务STM(Software Transactional Memory), 目的是更加容易使用,但是按下葫芦飘起瓢,还是带来了bugs和复杂性.
我很惊讶听到去年3月QCon上一个演讲, LMAX是一种新的零售的金融交易平台。它的业务创新 – 允许任何人在一系列的金融衍生产品交易。这就需要非常低的延迟,非常快速的处理,因为市场变化很快,这个零售平台因为有很多人同时操作自然具备了复杂性,用户越多,交易量越大,不断快速增长。
鉴于多核心思想的转变,这种苛刻的性能自然会提出一个明确的并行编程模型 ,但是他们却提出用一个线程处理6百万订单,而且是每秒,在通用的硬件上。
通过低延迟处理大量交易,取得低延迟和高吞吐量,而且没有并发代码的复杂性,他们是怎么做到呢?现在LMAX已经产品化一段时间了,现在应该可以揭开其神秘而迷人的面纱了。
整体结构
结构如图:
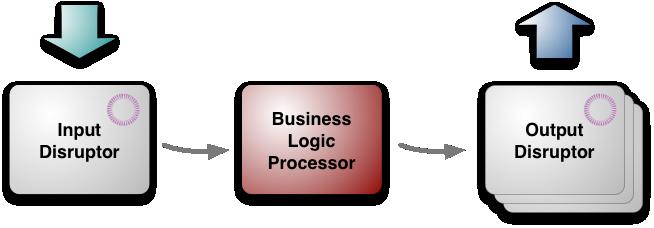
图一:LMAX架构的三大块)
从最高层次看,架构有三个部分:
-
-
业务逻辑处理器business logic processor[5]
-
输入input disruptor
-
输出output disruptors
-
业务逻辑处理器处理所有的应用程序的业务逻辑,这是一个单线程的Java程序,纯粹的方法调用,并返回输出。不需要任何平台框架,运行在JVM里,这就保证其很容易运行测试环境。
Although the Business Logic Processor can run in a simple environment for testing, there is rather more involved choreography to get it to run in a production setting. Input messages need to be taken off a network gateway and unmarshaled, replicated and journaled. Output messages need to be marshaled for the network. These tasks are handled by the input and output disruptors. Unlike the Business Logic Processor, these are concurrent components, since they involve IO operations which are both slow and independent. They were designed and built especially for LMAX, but they (like the overall architecture) are applicable elsewhere.
业务逻辑处理器
全部驻留在内存中
业务逻辑处理器有次序地取出消息,然后运行其中的业务逻辑,然后产生输出事件,整个操作都是在内存中,没有数据库或其他持久存储。将所有数据驻留在内存中有两个重要好处:首先是快,没有IO,也没有事务,其次是简化编程,没有对象/关系数据库的映射,所有代码都是使用Java对象模型(广告:开源框架Jdonframework和JiveJdon也是全部基于内存和事件源,内存领域对象+事件驱动,看来这条路的方向是对的)。
使用基于内存的模型有一个重要问题:万一崩溃怎么办?电源掉电也是可能发生的,“事件”(Event Sourcing )概念是问题解决的核心,业务逻辑处理器的状态是由输入事件驱动的,只要这些输入事件被持久化保存起来,你就总是能够在崩溃情况下,根据事件重演重新获得当前状态。(NOSQL存储的基于事件的事务实现)
要很好理解这点可以通过版本控制系统来理解,版本控制系统提交的序列,在任何时候,你可以建立由申请者提交一个工作拷贝,版本控制系统是一个复杂的商业逻辑处理器,而这里的业务逻辑处理只是一个简单的序列。
因此,从理论上讲,你总是可以通过后处理的所有事件的商业逻辑处理器重建的状态,但是实践中重建所有事件是耗时的,需要切分,LMAX提供业务逻辑处理的快照,从快照还原,每天晚上系统不繁忙时构建快照,重新启动商业逻辑处理器的速度很快,一个完整的重新启动 – 包括重新启动JVM加载最近的快照,和重放一天事件 – 不到一分钟。
快照虽然使启动一个新的业务逻辑处理器的速度,但速度还不够快,业务逻辑处理器在下午2时就非常繁忙甚至崩溃,LMAX就保持多个业务逻辑处理器同时运行,每个输入事件由多个处理器处理,只有一个处理器输出有效,其他忽略,如果一个处理器失败,切换到另外一个,这种故障转移失败恢复是事件源驱动 (Event Sourcing)的另外一个好处。
通过事件驱动(event sourcing)他们也可以在处理器之间以微秒速度切换,每晚创建快照,每晚重启业务逻辑处理器, 这种复制方式能够保证他们没有当机时间,实现24/7.
事件方式是有价值的因为它允许处理器可以完全在内存中运行,但它有另一种用于诊断相当大的优势:如果出现一些意想不到的行为,事件副本们能够让他们在开发环境重放生产环境的事件,这就容易使他们能够研究和发现出在生产环境到底发生了什么事。
这种诊断能力延伸到业务诊断。有一些企业的任务,如在风险管理,需要大量的计算,但是不处理订单。一个例子是根据其目前的交易头寸的风险状况排名前 20位客户名单,他们就可以切分到复制好的领域模型中进行计算,而不是在生产环境中正在运行的领域模型,不同性质的领域模型保存在不同机器的内存中,彼此不影响。
性能优化
正如我解释,业务逻辑处理器的性能关键是按顺序地做事(其实并不愚蠢 并行做就聪明吗?),这可以让普通开发者写的代码处理10K TPS. 如果能精简代码能够带来100K TPS提升. 这需要良好的代码和小方法,当然,JVM Hotspot的缓存微调,让其更加优化也是必须的。
相关文章
- 暂无相关文章
用户点评