小延迟大吞吐:LMAX架构(1)(2)
以下两段未翻译…….调试方面。
It took a bit more cleverness to go up another order of magnitude. There are several things that the LMAX team found helpful to get there. One was to write custom implementations of the java collections that were designed to be cache-friendly and careful with garbage[8]. An example of this is using primitive java longs as hashmap keys with a specially written array backed Map implementation (LongToObjectHashMap). In general they’ve found that choice of data structures often makes a big difference, Most programmers just grab whatever List they used last time rather than thinking which implementation is the right one for this context.[9]
Another technique to reach that top level of performance is putting attention into performance testing. I’ve long noticed that people talk a lot about techniques to improve performance, but the one thing that really makes a difference is to test it. Even good programmers are very good at constructing performance arguments that end up being wrong, so the best programmers prefer profilers and test cases to speculation.[10] The LMAX team has also found that writing tests first is a very effective discipline for performance tests.
编程模型
以一个简单的非LMAX的例子来说明。想象一下,你正在为糖豆使用信用卡下订单。一个简单的零售系统将获取您的订单信息,使用信用卡验证服务,以检查您的信用卡号码,然后确认您的订单 – 所有这些都在一个单一过程中操作。当进行信用卡有效性检查时,服务器这边的线程会阻塞等待,当然这个对于用户来说停顿不会太长。
在MAX架构中,你将此单一操作过程分为两个,第一部分将获取订单信息,然后输出事件(请求信用卡检查有效性的请求事件)给信用卡公司. 业务逻辑处理器将继续处理其他客户的订单,直至它在输入事件中发现了信用卡已经检查有效的事件,然后获取该事件来确认该订单有效。
这种异步事件驱动方式确实不寻常,虽然使用异步提高应用程序的响应是一个熟悉的技术。它还可以帮助业务流程更弹性,因为你必须要更明确的思考与远程应用程序打交道的不同之处。
这个编程模型第二个特点在于错误处理。传统模式下会话和数据库事务提供了一个有用的错误处理能力。如果有什么出错,很容易抛出任何东西,这个会话能够被丢弃。如果一个错误发生在数据库端,你可以回滚事务。
LMAX的内存模式(in-memory structures)在于持久化输入事件,如果有错误发生也不会从内存中离开造成不一致的状态。但是因为没有回滚机制,LMAX投入了更多精力,确保输入事件在实施任何内存状态影响前有效地持久化,他们发现这个关键是测试,在进入生产环境之前尽可能发现各种问题,确保持久化有效。
Disruptors的输入和输出
尽管业务逻辑是在单个线程中实现的,但是在我们调用一个业务对象方法之前,有很多任务需要完成. 原始输入来自于消息形式,这个消息需要恢复成业务逻辑处理器能够处理的形式。事件源Event Sourcing依赖于让所有输入事件持久化,这样每个输入消息需要能够存储到持久化介质上,最后整个架构还有赖于业务逻辑处理器的集群. 同样在输出一边,输出事件也需要进行转换以便能够在网络上传输。
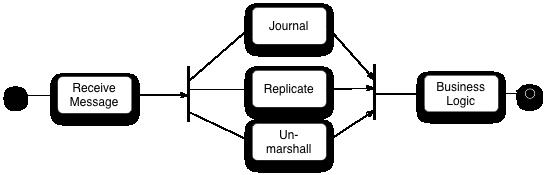
如图复制和日志是比较慢的。所有业务逻辑处理器避免最任何IO处理,所有这些任务都应该相对独立,他们需要在业务逻辑处理器处理之前完成,它们可以以任何次序方式完成,这不同意业务逻辑处理器需要根据交易自然先后进行交易,这些都是需要的并发机制。
为了这个并发机制,他们开发了disruptor的开源组件。
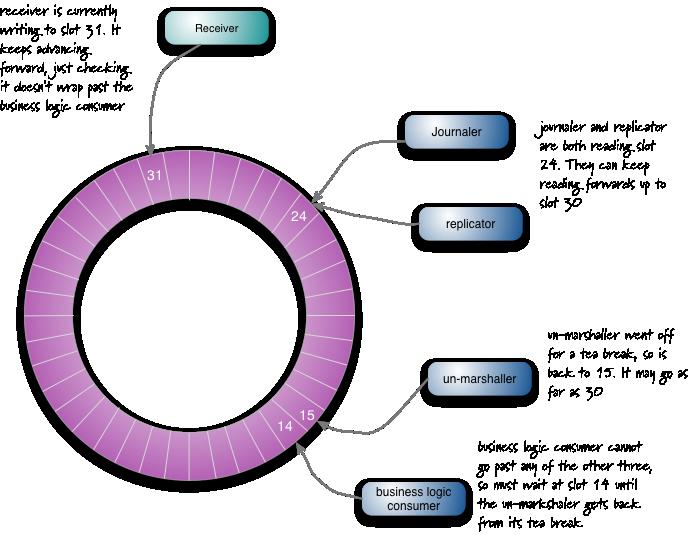
Disruptor可以看成一个事件监听或消息机制,在队列中一边生产者放入消息,另外一边消费者并行取出处理. 当你进入这个队列内部查看,发现其实是一个真正的单个数据结构:一个ring buffer. 每个生产者和消费者都有一个次序计算器,以显示当前缓冲工作方式.每个生产者消费者写入自己次序计数器,能够读取对方的计数器,生产者能够读取消费者的计算器确保其在没有锁的情况下是可写的,类似地消费者也要通过计算器在另外一个消费者完成后确保它一次只处理一次消息。
相关文章
- 暂无相关文章
用户点评