给jdk写注释系列之jdk1.6容器(10):Stack&Vector源码解析,jdkjdk1.6
分享于 点击 35216 次 点评:99
给jdk写注释系列之jdk1.6容器(10):Stack&Vector源码解析,jdkjdk1.6
本系列:
- 给jdk写注释系列之jdk1.6容器(1):ArrayList源码解析
- 给jdk写注释系列之jdk1.6容器(2):LinkedList源码解析
- 给jdk写注释系列之jdk1.6容器(3):Iterator设计模式
- 给jdk写注释系列之jdk1.6容器(4):HashMap源码解析
- 给jdk写注释系列之jdk1.6容器(5):LinkedHashMap源码解析
- 给jdk写注释系列之jdk1.6容器(6):HashSet源码解析&Map迭代器
- 给jdk写注释系列之jdk1.6容器(8):TreeSet、NavigableMap、NavigableSet源码解析
- 给jdk写注释系列之jdk1.6容器(9):Strategy设计模式之Comparable&Comparator接口
前面我们已经接触过几种数据结构了,有数组、链表、Hash表、红黑树(二叉查询树),今天再来看另外一种数据结构:栈。
什么是栈呢,我就不找它具体的定义了,直接举个例子,栈就相当于一个很窄的木桶,我们往木桶里放东西,往外拿东西时会发现,我们最开始放的东西在最底部,最先拿出来的是刚刚放进去的。所以,栈就是这么一种先进后出( First In Last Out,或者叫后进先出) 的容器,它只有一个口,在这个口放入元素,也在这个口取出元素。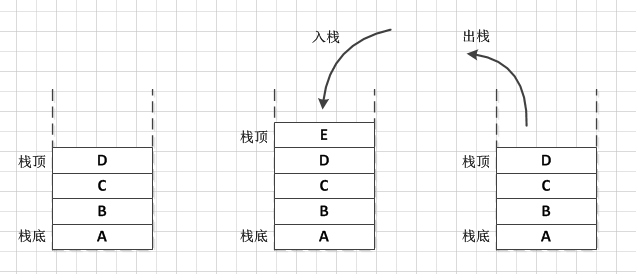 栈最主要了两个动作就是入栈和出栈操作,其实还是很容易的明白的对不对,那么我们接下来就看一下Jdk容器中的栈Stack是怎么实现的吧。
1.定义
栈最主要了两个动作就是入栈和出栈操作,其实还是很容易的明白的对不对,那么我们接下来就看一下Jdk容器中的栈Stack是怎么实现的吧。
1.定义
public
class Stack<E> extends Vector<E> {
我们发现Stack继承了Vector,Vector又是什么东东呢,看一下。
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
发现没有,Vector是List的一个实现类,其实Vector也是一个基于数组实现的List容器,其功能及实现代码和ArrayList基本上是一样的。那么不一样的是什么地方的,一个是数组扩容的时候,Vector是*2,ArrayList是*1.5+1;另一个就是Vector是线程安全的,而ArrayList不是,而Vector线程安全的做法是在每个方法上面加了一个synchronized关键字来保证的。但是这里说一句,Vector已经不官方的(大家公认的)不被推荐使用了,正式因为其实现线程安全方式是锁定整个方法,导致的是效率不高,那么有没有更好的提到方案呢,其实也不能说有,但是还真就有那么一个,Collections.synchronizedList(),这不是我们今天的重点不做深入探讨,回到Stack的实现上。
2.Stack&Vector底层存储
由于Stack是继承和基于Vector,那么简单看一下Vector的一些定义和方法源码:// 底层使用数组存储数据
protected Object[] elementData;
// 元素个数
protected int elementCount ;
// 自定义容器扩容递增大小
protected int capacityIncrement ;
public Vector( int initialCapacity, int capacityIncrement) {
super();
// 越界检查
if (initialCapacity < 0)
throw new IllegalArgumentException( "Illegal Capacity: " +
initialCapacity);
// 初始化数组
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
// 使用synchronized关键字锁定方法,保证同一时间内只有一个线程可以操纵该方法
public synchronized boolean add(E e) {
modCount++;
// 扩容检查
ensureCapacityHelper( elementCount + 1);
elementData[elementCount ++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
// 当前元素数量
int oldCapacity = elementData .length;
// 是否需要扩容
if (minCapacity > oldCapacity) {
Object[] oldData = elementData;
// 如果自定义了容器扩容递增大小,则按照capacityIncrement进行扩容,否则按两倍进行扩容(*2)
int newCapacity = (capacityIncrement > 0) ?
(oldCapacity + capacityIncrement) : (oldCapacity * 2);
if (newCapacity < minCapacity) {
newCapacity = minCapacity;
}
// 数组copy
elementData = Arrays.copyOf( elementData, newCapacity);
}
}
Vector就简单看到这里,其他方法Stack如果没有调用的话就不进行分析了,不明白的可以去看ArrayList源码解析。
3.peek()——获取栈顶的对象
/**
* 获取栈顶的对象,但是不删除
*/
public synchronized E peek() {
// 当前容器元素个数
int len = size();
// 如果没有元素,则直接抛出异常
if (len == 0)
throw new EmptyStackException();
// 调用elementAt方法取出数组最后一个元素(最后一个元素在栈顶)
return elementAt(len - 1);
}
/**
* 根据index索引取出该位置的元素,这个方法在Vector中
*/
public synchronized E elementAt(int index) {
// 越界检查
if (index >= elementCount ) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
// 直接通过数组下标获取元素
return (E)elementData [index];
}
4.pop()——弹栈(出栈),获取栈顶的对象,并将该对象从容器中删除
/**
* 弹栈,获取并删除栈顶的对象
*/
public synchronized E pop() {
// 记录栈顶的对象
E obj;
// 当前容器元素个数
int len = size();
// 通过peek()方法获取栈顶对象
obj = peek();
// 调用removeElement方法删除栈顶对象
removeElementAt(len - 1);
// 返回栈顶对象
return obj;
}
/**
* 根据index索引删除元素
*/
public synchronized void removeElementAt(int index) {
modCount++;
// 越界检查
if (index >= elementCount ) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
// 计算数组元素要移动的个数
int j = elementCount - index - 1;
if (j > 0) {
// 进行数组移动,中间删除了一个,所以将后面的元素往前移动(这里直接移动将index位置元素覆盖掉,就相当于删除了)
System. arraycopy(elementData, index + 1, elementData, index, j);
}
// 容器元素个数减1
elementCount--;
// 将容器最后一个元素置空(因为删除了一个元素,然后index后面的元素都向前移动了,所以最后一个就没用了 )
elementData[elementCount ] = null; /* to let gc do its work */
}
5.push(E item)——压栈(入栈),将对象添加进容器并返回
/**
* 将对象添加进容器并返回
*/
public E push(E item) {
// 调用addElement将元素添加进容器
addElement(item);
// 返回该元素
return item;
}
/**
* 将元素添加进容器,这个方法在Vector中
*/
public synchronized void addElement(E obj) {
modCount++;
// 扩容检查
ensureCapacityHelper( elementCount + 1);
// 将对象放入到数组中,元素个数+1
elementData[elementCount ++] = obj;
}
6.search(Object o)——返回对象在容器中的位置,栈顶为1
/**
* 返回对象在容器中的位置,栈顶为1
*/
public synchronized int search(Object o) {
// 从数组中查找元素,从最后一次出现
int i = lastIndexOf(o);
// 因为栈顶算1,所以要用size()-i计算
if (i >= 0) {
return size() - i;
}
return -1;
}
7.empty()——容器是否为空
/**
* 检查容器是否为空
*/
public boolean empty() {
return size() == 0;
}
到这里Stack的方法就分析完成了,由于Stack最终还是基于数组的,理解起来还是很容易的(因为有了ArrayList的基础啦)。
虽然jdk中Stack的源码分析完了,但是这里有必要讨论下,不知道是否发现这里的Stack很奇怪的现象,
(1)Stack为什么是基于数组实现的呢?
我们都知道数组的特点:方便根据下标查询(随机访问),但是内存固定,且扩容效率较低。很容易想到Stack用链表实现最合适的。
(2)Stack为什么是继承Vector的?
继承也就意味着Stack继承了Vector的方法,这使得Stack有点不伦不类的感觉,既是List又是Stack。如果非要继承Vector合理的做法应该是什么:Stack不继承Vector,而只是在自身有一个Vector的引用,聚合对不对?
唯一的解释呢,就是Stack是jdk1.0出来的,那个时候jdk中的容器还没有ArrayList、LinkedList等只有Vector,既然已经有了Vector且能实现Stack的功能,那么就干吧。。。
既然用链表实现Stack是比较理想的,那么我们就来尝试一下吧:
import java.util.LinkedList;
public class LinkedStack<E> {
private LinkedList<E> linked ;
public LinkedStack() {
this.linked = new LinkedList<E>();
}
public E push(E item) {
this.linked .addFirst(item);
return item;
}
public E pop() {
if (this.linked.isEmpty()) {
return null;
}
return this.linked.removeFirst();
}
public E peek() {
if (this.linked.isEmpty()) {
return null;
}
return this.linked.getFirst();
}
public int search(E item) {
int i = this.linked.indexOf(item);
return i + 1;
}
public boolean empty() {
return this.linked.isEmpty();
}
}
看完后,你说我cha,为什么这么简单,就这么点代码。因为这里使用的LinkedList实现的Stack,记得在LinkedList中说过,LinkedList实现了Deque接口使得它既可以作为栈(先进后出),又可以作为队列(先进先出)。那么什么是队列呢?Queue见吧!
Stack&Vector 完!
用户点评