Java集合-Map,java集合类详解和使用
分享于 点击 14206 次 点评:81
Java集合-Map,java集合类详解和使用
Map集合
特点
- 双列集合<K,V>
- Key 和 Value一一对应
- K不允许重复,V可以重复
- K,V的数据类型可以相同,也可不同
常用方法
| 方法 | 描述 |
|---|---|
| V put(K key, V value) | 将指定的值与该映射中的指定键相关联(可选操作)。 |
| V remove(Object key) | 如果存在(从可选的操作),从该地图中删除一个键的映射。 |
| V get(Object key) | 返回到指定键所映射的值,或 null如果此映射包含该键的映射。 |
| boolean containsKey(Object key) | 如果此映射包含指定键的映射,则返回 true 。 |
| Set |
返回此地图中包含的键的Set视图。 |
| Set<Map.Entry<K,V>> entrySet() | 返回此地图中包含的映射的Set视图。 |
内部接口:Entry<K,V>
作用:当Map集合创建,就会创建一个Entry对象,用来存储键值对。
测试代码
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
/**
* 测试Map集合的常用方法
* add、remove、get、containKey、keySet、entrySet
*/
public class TestMap {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
// put的返回值是被替代的V,如果原来没有就是null
System.out.println(map.put("1001", "张三"));
System.out.println(map.put("1001", "张三丰"));
map.put("1002", "李四");
map.put("1003", "王五");
System.out.println(map);
// remove返回被删除的V,Key不存在则返回null
System.out.println(map.remove("1005"));
System.out.println(map.remove("1003"));
System.out.println(map);
// get返回key对应的value, 无则null
System.out.println(map.get("1002"));
System.out.println(map.get("1003"));
// containsKey 包含key返回true
System.out.println(map.containsKey("1002"));
System.out.println(map.containsKey("1003"));
System.out.println("遍历方式1:将所有key取出来存到set集合");
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.println("K:"+key+" V:"+map.get(key));
}
System.out.println("遍历方式2:将所有Entry<K,V>对象取出来存到set集合");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
}
}
运行结果
null
张三
{1003=王五, 1002=李四, 1001=张三丰}
null
王五
{1002=李四, 1001=张三丰}
李四
null
true
false
遍历方式1:将所有key取出来存到set集合
K:1002 V:李四
K:1001 V:张三丰
遍历方式2:将所有Entry<K,V>对象取出来存到set集合
1002=李四
1001=张三丰
HashMap(重点)
基于哈希表的实现的Map接口。 此实现提供了所有可选的Map操作,并允许null值和null键。
底层原理
底层是哈希表,查询速度超级快!
JDK8之前:数组+链表
JDK8之后:数组+链表 / 数组+红黑树
HashMap面试需要更深的理解,深入底层!
目前停留于了解原理,掌握运用。
测试代码
存储自定义对象
首先创建一个学生类
package map;
public class Student{
private int id;
private String name;
private int age;
public Student() {
}
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
测试类
package map;
import java.util.HashMap;
/**
* 若以自定义类作键存放,必须说明键重复的规则
* 实体类重写hashCode方法和equals方法
* 比如学生类中,同名不一定是同一个对象,同学号说明是同一个学生
*/
public class TestHashMap {
public static void main(String[] args) {
Student student1 = new Student(1001, "张三", 18);
Student student2 = new Student(1002, "李四", 17);
Student student3 = new Student(1001, "张三", 19);
Student student4 = new Student(1004, "李四", 20);
HashMap<Student, String> map = new HashMap<>();
map.put(student1, "第一名");
map.put(student2, "第二名");
map.put(student3, "第三名");
map.put(student4, "第四名");
System.out.println(map);
}
}
运行结果
{Student{id=1004, name='李四', age=20}=第四名, Student{id=1002, name='李四', age=17}=第二名, Student{id=1001, name='张三', age=18}=第一名, Student{id=1001, name='张三', age=19}=第三名}
此时观察student1 和 student3 的学号相同,对象重复,为什么还会添加到map中呢?
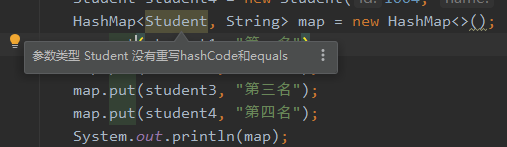
有提示要重写Student类的hashCode方法和equals方法。
修改后的Student.java
package map;
import java.util.Objects;
public class Student{
private int id;
private String name;
private int age;
public Student() {
}
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
// ...get/set省略
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return id == student.id;
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}
再次运行测试类的代码得到的结果
{Student{id=1001, name='张三', age=18}=第三名, Student{id=1002, name='李四', age=17}=第二名, Student{id=1004, name='李四', age=20}=第四名}
分析:第一次添加1001学生时,value是第一名,再次遇到1001学生,覆盖了原来的value
深入理解HashMap
更加详细的学习会写到另一篇
LinkedHashMap
哈希表和链表实现的Map接口,具有可预测的迭代次序。有序集合!
public class LinkedHashMap<K,V>extends HashMap<K,V>implements Map<K,V>{}
底层原理
- 哈希表 -> 继承自HashMap
- 链表 -> 记录元素顺序
测试代码
import java.util.*;
public class TestLinkedHashMap {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put("1001", "张三");
map.put("1002", "李四");
map.put("1003", "王五");
map.put("1004", "赵六");
System.out.println("map的数据无序,取出的结果与存入顺序不一致:");
System.out.println(map);
System.out.println();
LinkedHashMap<String, String> link = new LinkedHashMap<>();
link.put("1001", "张三");
link.put("1002", "李四");
link.put("1003", "王五");
link.put("1004", "赵六");
System.out.println("在map外层加一层链表记录元素存入的顺序:");
System.out.println(link);
}
}
运行结果
map的数据无序,取出的结果与存入顺序不一致:
{1004=赵六, 1003=王五, 1002=李四, 1001=张三}
在map外层加一层链表记录元素存入的顺序:
{1001=张三, 1002=李四, 1003=王五, 1004=赵六}
Hashtable
Hashtable 和 Vector 一样都是上古级别的集合,在jdk1.2版本之后被更先进的HashMap及ArrayList集合取代。
值得注意的是,Hashtable的子类Properties目前依旧活跃着,它是唯一和IO流结合的集合。
Hashtable 与 HashMap 的区别
底层都是哈希表,元老级更注重线程安全。
Hashtable
- 线程安全—>单线程集合—>速度慢
- 不能存储 null ,K,V都不可以
HashMap
- 线程不安全—>多线程集合—>速度快
- 可以存储 null
- K 只能存储一个 null ,保证K的唯一性
- V 可以存储任意个 null
测试代码
import java.util.HashMap;
import java.util.Hashtable;
public class TestHashtable {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put(null, null);
map.put("A", null);
map.put(null, "B");
System.out.println(map);
Hashtable<String, String> table = new Hashtable<>();
//table.put(null, null);//NullPointerException
//table.put("A", null);//NullPointerException
//table.put(null, "B");//NullPointerException
System.out.println(table);
}
}
运行结果
{null=B, A=null}
{}
HashMap中以null作为键时,再次添加null的键会覆盖之前的value值。
Hashtable只要涉及到null,就会报空指针异常。
集合练习
相关文章
- 暂无相关文章
用户点评